As some of you know, we are supported by NLNet through the EU’s Next Generation Internet (NGI0) programme, which stimulates network research and development of the free Internet, to do the architecture for scaling up our infrastructure. We are additionally supported by the Filecoin Foundation, who support the growth of the distributed web, through a devgrant, whichs helps us to actually implement the scale-out.
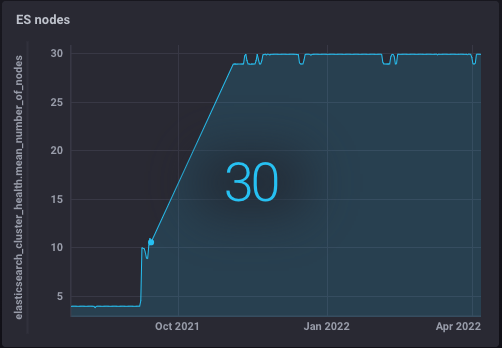
We successfully followed our plan to move step-by-step from one server to a 5 node cluster setup, then to 15 servers, and now we are scaling up through 30, 50 and up to 100 nodes. This puts us on the path to 1000 hits per second; a thousand users every second searching something. We are now in the middle of the way, running on 30 servers. The current experiment is for us to learn how to scale our infrastructure up, until 100 nodes.
Right now, we have indexing capacity of 20 TB, and we are planning to have 100 TB by the end of our scale-out experiment. It is a real challenge as a typical computer stores around 1 TB and copying this 1 TB from one computer to another can take hours.
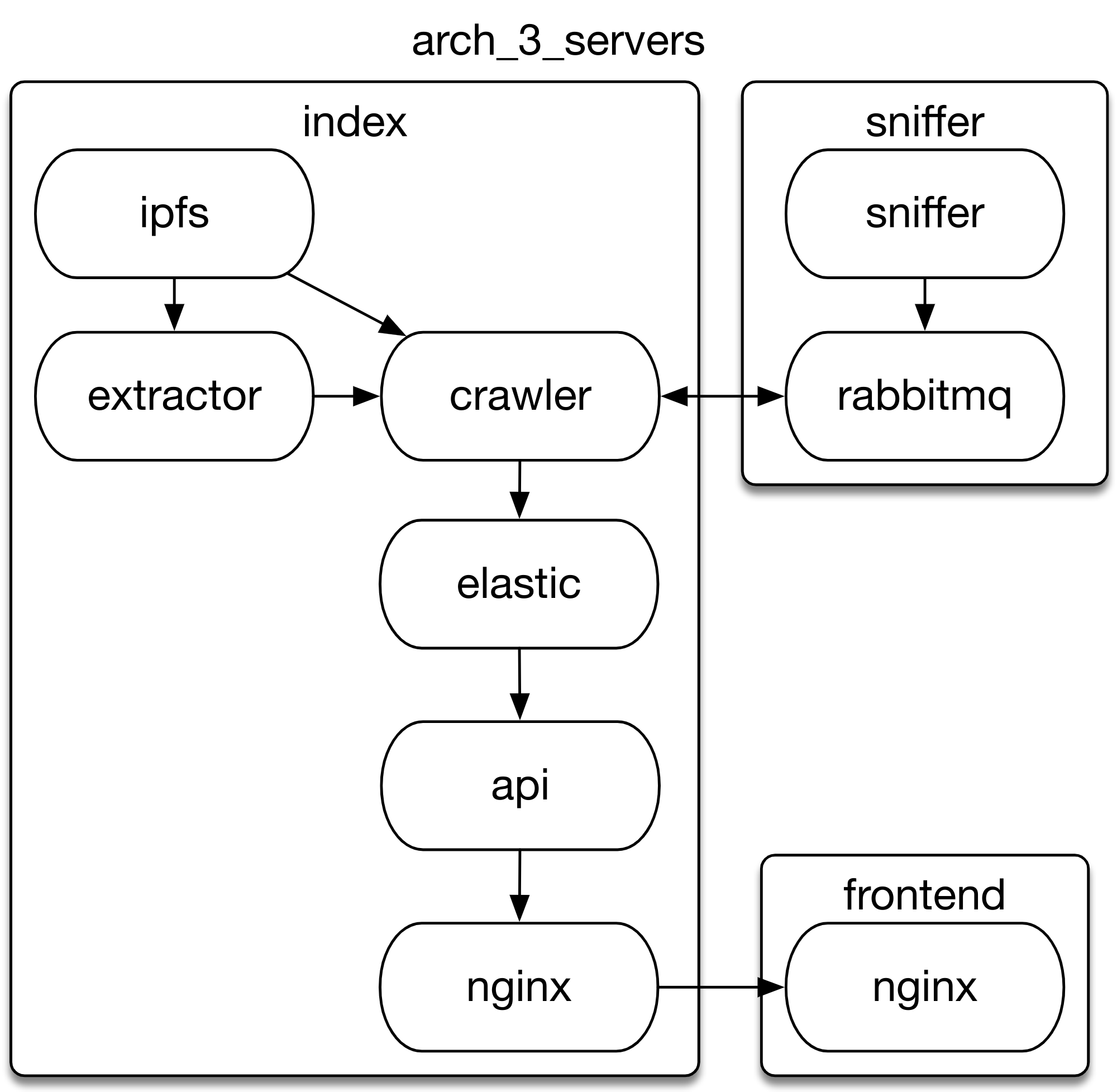
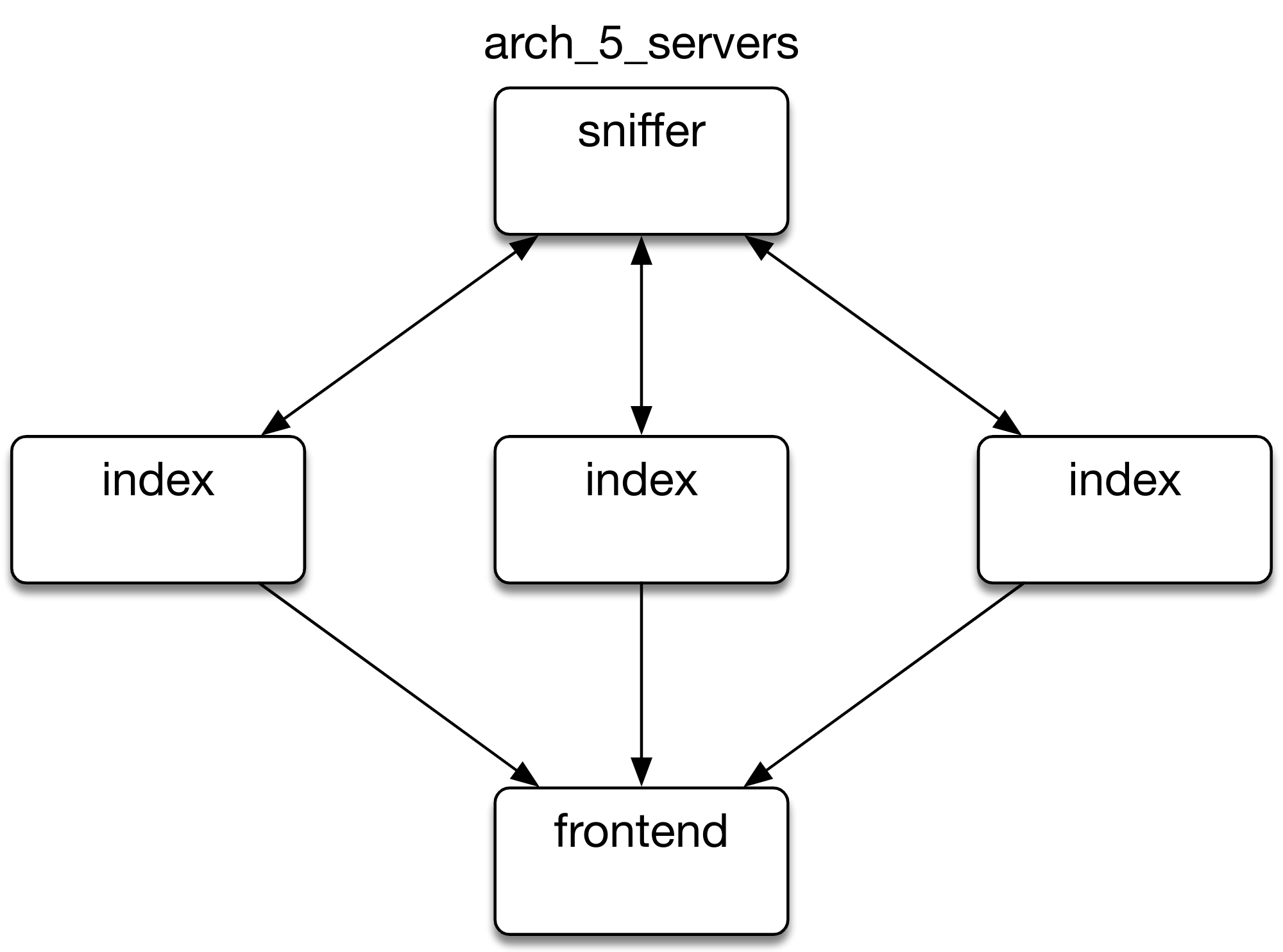
But let us walk you through what have been going on in our headquarters recently
One of our ways to limit costs is to use physical servers instead of, very popular, cloud servers. This choice is also recommended by Elasticsearch, which we use. After a careful research, we have chosen Hetzner hosting, a German company that provides climate neutral servers, which was also important for us. Why exactly we decided to use bare metal servers? We like to keep an eye on what’s going on. We are able to track temperature and delays on individual discs, we know about every hardware failure, every unusual behaviour pattern and if we were using virtual server we wouldn’t know all these things. Also, the costs are about a factor 10 lower, because we use a lot of data, memory, storage, CPU and I/O.
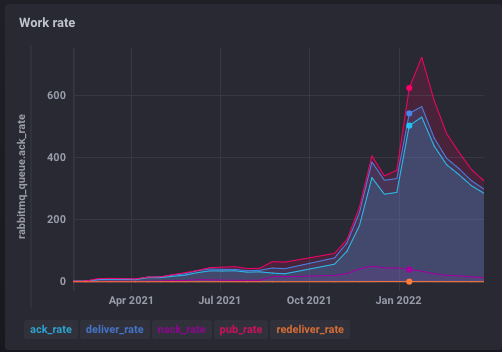
In the beginning we have been indexing on one server, the most powerful server at Hetzner’s and of course at one point it ran full. We had to shut down the indexing, because we weren’t able to take new files. All this was caused by the fact that in the previous year we made some changes to the crawler (the part that extracts data from the hashes and indexes them) that made it about 100 times faster. So suddenly, instead of indexing 0.1 document per second, we were indexing about 10 documents per second. The consequence was obvious — scaling up the hosting.
🛠 We weren’t expecting a totally smooth transition, as we know that designing a perfect cluster is almost impossible at the beginning.
So, when we went up to 2 servers, and there were no problems, it was a great surprise. Our deployments are automated, we are using Ansible. This allowed us in the past to change a hosting company in about two days. It is a reasonable solution to deal with multiple servers. Instead of executing a gazillion commands for every server manually, and checking the results, Ansible does this for us. But the architecture, what server does what, and telling that in the correct way to Ansible, was the challenge.
Redundancy
Later we moved to 3 servers, and we had reached the point where when something breaks in one of them, the page is still up. If you design a larger server architecture, there will always be, depending on the size of your system, some number of servers that perform badly. They are guaranteed to crash at one point, and by expecting it, there will be no degradation of the service as a result. However, to be safe while this is happening, we needed to prepare a fault-tolerant cluster. It means, among other things, distributing sliced parts of data (called shards) between multiple nodes. Then, creating a copy of every shard and allocating it to a different node in a way that no original and its copy live on the same node. The replica shard is always up-to-date with the original. That make sure that even if some servers are down, all the data is available.
These shards, logical and physical divisions of an index, need to be tuned really carefully to the size of the server and size of our constantly growing data.
Although it comes with some disadvantages, horizontal partitioning, by reducing index size, greatly improves search performance.
Coordination through dedicated master nodes
We also introduced the difference between data and master nodes. Master nodes take care of allocating chosen shards of our data on chosen servers, and making sure the servers know about each other. They are also maintaining information including shards’ localization (which node are they on), index mapping, and performing healthchecks. We have to adjust numbers of data nodes to the growing architecture in order to maintain cluster stability, but the amount of master nodes always stays at 3.
Data replication
Last but not least, we were working on data replication. IPFS Search by definition is an entry to a lot of data, which must not be lost. We set our replication factor to 2 which means that we keep 3 copies of data in our cluster, 1 primary and 2 replicas. In other words, even if a primary is lost, its replica can be made a primary until the recovery.
In addition to this, we make daily snapshots of our index, so that even if we accidentally delete all our data (e.g. human error or end of the World…) we keep a backup.
So we came a long way from 1 document to 500 documents being indexed or updated at the same time, and we’re still improving and optimizing various part of this system. The challenge here was (and still is) finding a golden way to tune the shards, and keep our cluster healthy and balanced.