Anatomy of a search engine
In previous posts, we’ve covered the development of frontend filters, described progress on scaling up the cluster architecture, and glanced at the importance of web security.
Now it is time to dive a little deeper into what ipfs-search.com, and basically any modern search engine, consists of.
As this is a very complex topic, we will take the liberty here of viewing just a few selected elements.
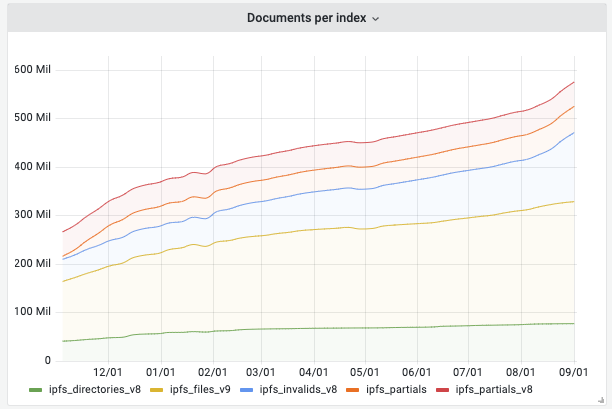
Our latest statistics show that our index is growing rapidly. We store 20 TB of searchable data. Currently, every day, half a million documents are added to the index.
Let’s take a look at how is it done. Here we have the elements that are responsible for catching this data, classifying it, and giving them correct labels.
A network sniffer
If you go through ipfs-search.com docs, you can read in the documentation that our search “…sniffs the DHT gossip and indexes file and directory hashes”.
Sounds cool, but what does that even mean?
 |
|---|
| Jurriaan Schulman, CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons |
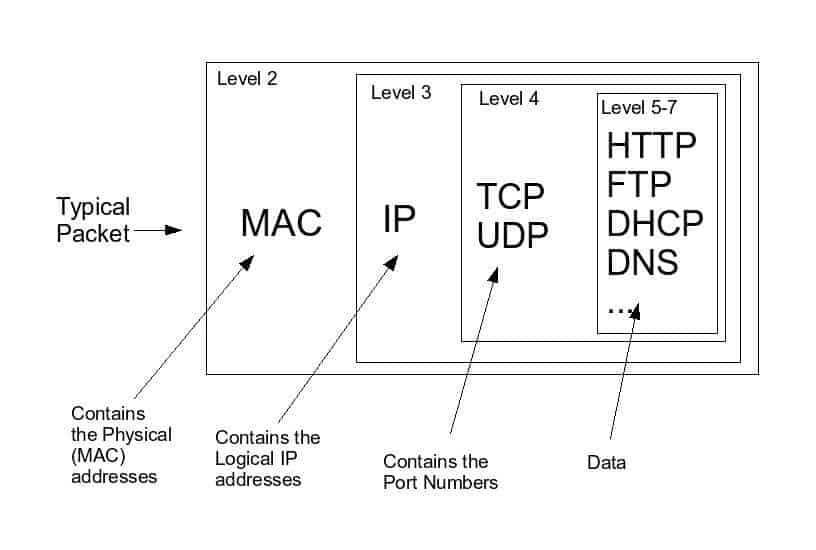
When we send information over a computer network, it is broken down into smaller units. They are the smallest units of network communication, called data packets. The sender’s node (which is just a device connected to a network) breaks down each piece of information into these smallest units, and after completing their journey to the receiver’s node, they are reassembled into their originals.
 |
|---|
| https://commons.wikimedia.org/wiki/File:Network_packet.jpg, via Wikimedia Commons |
{kind=link}
Data packets are commonly monitored by sysadmins for security reasons, to search for anomalies in traffic, and perform maintenance.
Intercepting data packets on a computer network is called packet sniffing, and it’s a term that is normally used in information security and network diagnostics. We recognize two ways of using it, legal and not so. It’s often how our governments listen in on our private communication and in the past, was commonly used by hackers for identity theft — stealing credit cards, passwords, etc. (Nowadays, most communication is encrypted, but creepy organisations like the NSA store all of your data and are likely able to break even modern strong encryption.)
The sniffing process looks similar to wiring a phone or eavesdropping behind the door, although it requires way more than only gathering data.
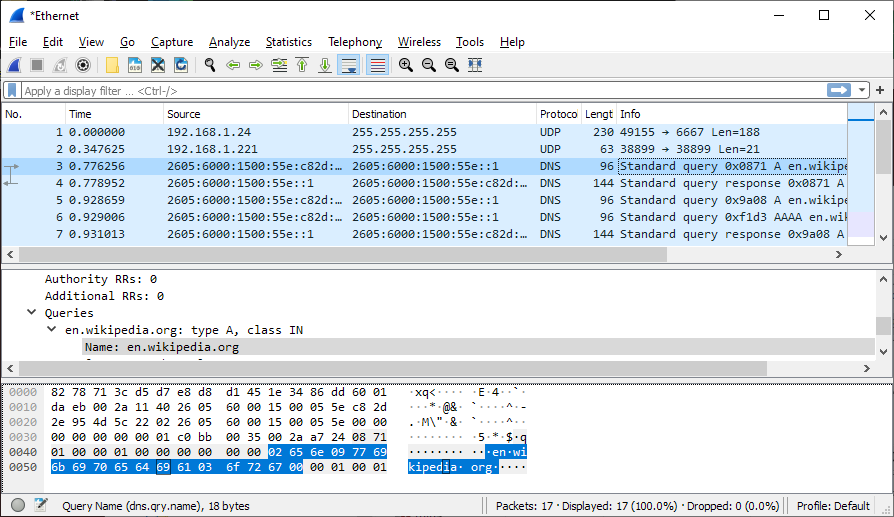
A sniffer itself is a piece of software (like, for example, Wireshark, which provides GUI and some helpful analytics tools) that you connect to a computer network to see the traffic.
 |
|---|
| Wireshark, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons |
ipfs-search.com sniffer
Our sniffer does not commit any crimes though. It’s based on the existing Hydra-Booster, “A new type of DHT (Distributed Hash Tables) node designed to accelerate the Content Resolution & Content Providing on the IPFS Network. A (cute) Hydra with one belly full of records and many heads (Peer IDs) to tell other nodes about them, charged with rocket boosters to transport other nodes to their destination faster.”
 |
|---|
| Hydra-booster |
To make it more useful for our purposes, we created a ‘middleware’/proxy between the part in IPFS/libp2p that stores what hosts have, so that every time it learns about something new, it gets passed to our crawler infrastructure.
Our sniffer is currently run on a single node, where we do deduplication of sniffed content. We are upgrading our architecture to allow for distributed sniffing of new content from IPFS’s DHT.
📢 ipfs-search.com sniffer currently uses 12 heads to process about 3000 hashes per second.
Gossip
Then we just need gossip.
 |
|---|
| CC-BY-NC-SA 4.0 via SL Enquirer |
Exactly the same way when people go to the café to exchange important or less important information, in a peer-to-peer network (like Libp2p/IPFS, BitTorrent, or other content-addressed storage systems) nodes talk to other nodes about the content they have.
 |
|---|
| Scott Martin, CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0, via Wikimedia Commons |
They have rather simple conversations going on, like “Where is this file? Have you seen it?”, “Which node has it?”, “It was here, but now it’s there.” etc.
📢 So how does ipfs-search.com do content discovery? How do we know what’s on IPFS?
For the network, we’re just a bunch of nodes, we listen to other nodes announcing what’s available. When we hear the message saying “I have this file, you can download it from me” a small signal passes through our network, and our crawler (the infrastructure that extracts metadata) gets the file and indexes it.
We store them in our database which lives on the cluster consisting of several servers which each index and search about 2 TB. So on the one side, we have crawlers that capture, index, and extract metadata whenever the sniffer finds new content, and on the client side, there is ipfs-search.com, our beautiful frontend. When a user searches for something, they talk to our database, and this is where the result of their query comes from.
A crawler
 |
|---|
| CC BY-NC-SA 2.0 by Héctor García |
A typical search engine also works with web crawlers. A crawler, or sometimes web spider, or, surprisingly, a spiderbot, is a bot, another piece of software, that visits webpages and indexes content that is uploaded by the users. It is also necessary to keep this content up to date and can be helpful with validating hyperlinks or HTML code.
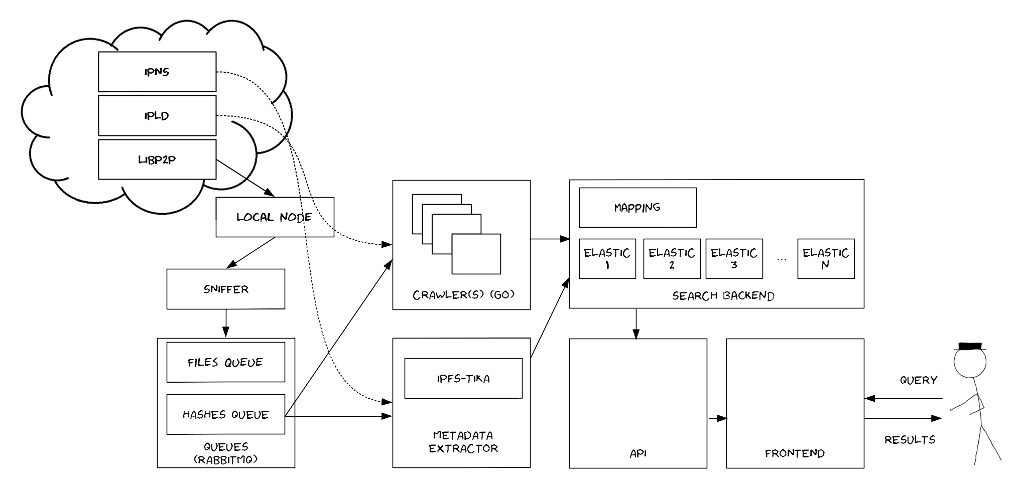 |
|---|
| Sketch of the ipfs-search.com architecture |
The ipfs-search.com crawler is also the component that orchestrates the process of extracting metadata from all data that is flowing through our network.
For this job, we use Apache’s Tika, for which we developed the highly efficient streaming tika-extractor, that gets a blob of bits and bytes thrown at its server by the crawler and puts a label: This is a music file, that is a text file, these are an author and a title… We made a special component that asynchronously requests data over our IPFS node, which makes this process more efficient.
{
"metadata": {
"xmpDM:genre": [
"Soundtrack"
],
"xmpDM:composer": [
"Nobuo Uematsu"
],
"X-Parsed-By": [
"org.apache.tika.parser.DefaultParser",
"org.apache.tika.parser.mp3.Mp3Parser"
],
"creator": [
""
],
"xmpDM:album": [
"\"Final Fantasy IX\" Original Soundtrack, Disk 4"
],
"xmpDM:trackNumber": [
"24"
],
"xmpDM:releaseDate": [
"2000"
],
"meta:author": [
""
],
"xmpDM:artist": [
""
],
"dc:creator": [
""
],
"xmpDM:audioCompressor": [
"MP3"
],
"resourceName": [
"24-Coca Cola TV CM 1.mp3"
],
"title": [
"Coca Cola TV CM 1"
],
"xmpDM:audioChannelType": [
"Stereo"
],
"version": [
"MPEG 3 Layer III Version 1"
],
"xmpDM:logComment": [
"eng - \nhttp://www.ffdream.com"
],
"xmpDM:audioSampleRate": [
"44100"
],
"channels": [
"2"
],
"dc:title": [
"Coca Cola TV CM 1"
],
"Author": [
""
],
"xmpDM:duration": [
"20218.76953125"
],
"Content-Type": [
"audio/mpeg"
],
"samplerate": "-\"44100\""
},
"version": 2,
"type": "file"
}
A bitswap protocol
It is worth mentioning, that IPFS is built on the protocol called bitswap where basically nodes trade data, exchanging a want-have request. If you want to download something, the way to get it is to have something that somebody else wants. This is how the network balances itself.
Summary
So basically, what ipfs-search.com does is: while nodes (all the computers that are connected to IPFS) talk to each other about available resources, the sniffer (another node), listens to this communication, and extracts hashes. When something is interesting, the crawler extracts data from the hashes and indexes them.
Of course, there is more to it. There are other processes under the hood, such as queuing, which is done using RabbitMQ, or our search API microservice. We refer those interested to our documentation.
Taking it further
In April Protocol Labs released the first production of the Network Indexer which makes searching (by CID or multihash) content-addressable data networks like IPFS and Filecoin possible. This is a decisive step towards a goal that also is in our line of work: easier and more accessible fetching of data across the IPFS network.
We might be looking at the option of combining these two indexing technologies. The result could be exciting.
Also, we’ll be moving to a different queuing system where we can have multiple sniffers and/or have them integrated with our IPFS nodes.
Resources: