Decentralised search: from dream to reality
At the beginning of May 2022, distributed web specialists from redpencil.io and ipfs-search.com conducted an experiment to run a fully distributed search index at ipfs-search.com. The experiment was created and performed by Aad Versteden, together with Elena Poelman, and was based on the research by professor Pieter Colpaert of Ghent University.
In our short talk, Aad Versteden, also co-founder and CEO of redpencil.io, shares the general concept of decentralization, the design, and procedure of the experiment as well as his insights for the future of distributed search.
ZM: How did redpencil.io come to work with ipfs-search.com? What attracted you to them?
AV: We showed interest in ipfs-search.com because discovery is a cornerstone of new web technologies. So, when we noticed that their services had gone down, we reached out to see if we could help. We work towards opening up the internet, and having a golden tool like ipfs-search.com disappear was not something we were going to ignore.
What’s more, we have chosen the distributed search route because running servers on this scale wouldn’t be financially feasible forever. As ipfs-search.com grows, I think there will be a funding gap that we won’t be able to cover (the search is growing faster than redpencil.io). The other team members there don’t have much experience with Linked Data technologies. So it seems that there is scope for some breakthroughs.
As redpencil.io works on distributed knowledge with tangible applications, it made sense that we execute this experiment.
Could you provide a little overview of the entire system in which the experiment was carried out?
IPFS itself allows you to share resources through their network and lets you share what you have used with others, peer-2-peer. The concept is quite simple: when someone downloads a certain file and their neighbour also wants it, it could be shared directly instead of going through some centralised server. In the case of Netflix, for example, this means that if I am at my parents’ house with my brother, and we are separately watching the same Netflix series, that series will only be downloaded to our home network once.
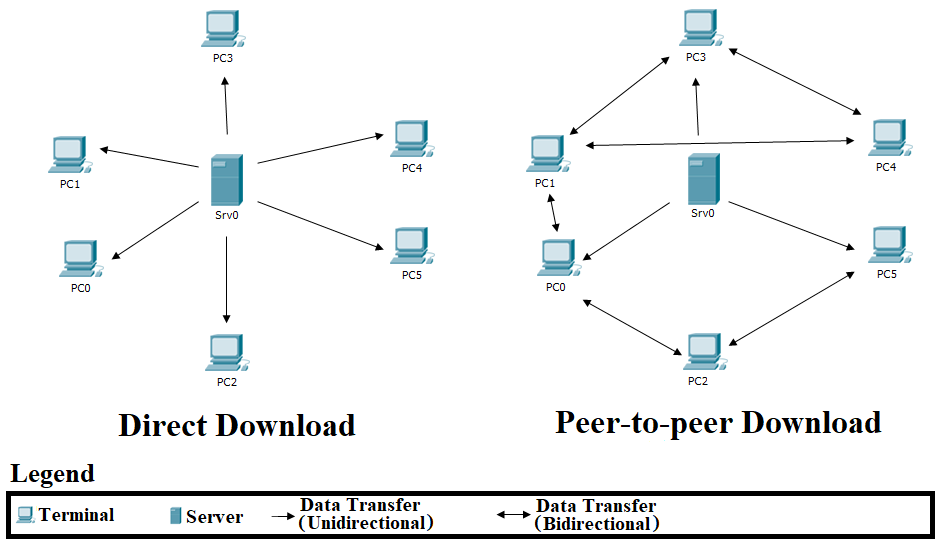 |
|---|
| Michel Bakni, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Common |
For search engines this is obviously a bit more complex, IPFS solves that for larger media files, but having a search index shared and used over the Internet is quite uncommon. There was research in the Linked Data space on how we can build resources that are shared and discoverable. If we consider the search index as a big folder of files hosted on IPFS, we find that we can reuse some of the technologies—mainly research by professor Pieter Colpaert.
What they have done is to say—if we are going to have a dataset, and we want to get information out of it, we shouldn’t be running a very heavy server to do that because then we are the ones who have to pay for that server. It’s better for the end users to have a slightly higher cost per query and for us, the providers, to have a vastly lower cost. The cheapest way to do something like that is basically to say: look, here’s the data in an index, go and figure out how to reuse it.
Sharing the index as a whole would mean people downloading gigabytes of data to answer a query. Nobody wants to do that, and it is not feasible.
So, prof. Colpaert found a way to split this data to retrieve only what is needed to perform a query. Purely by using Linked Data technologies. There is a solution for search engines, prefix search, and also for full-text search, but we haven’t tried full-text search.
What have you tried?
We implemented prefix search. It means that we took the full 2019 and 2020 datasets from ipfs-search.com, and created a split version of it. We had all the titles and looked at what letter they start with. The way it works is if someone searches for a title that starts with a ‘T’, they will be redirected to a page of the index with that letter or combination of letters. It narrows down the results so that for each letter searched—only one page is retrieved. These pages are small parts of the search index, so if my spouse also searched for the same letter(s), I would automatically provide her with my part of the index. It would not go through anyone else, it would remain on the local network.
 |
|---|
| Frontend view. Courtesy of redpencil.io |
Prefix search allows you to search for the beginning of the page title only. It breaks down the search query into letters and creates some sort of container for each letter’s results. It keeps narrowing down the search results until you get all records from the index that starts, let’s say, with “The sta”. This is great progress, but it is similar to an index of the library more than to the search engines we are familiar with nowadays.
So what exactly did this experiment involve?
Our experiment consisted of taking the ipfs-search.com database, titles, and some identifiers so that we knew where to find these resources, partitioning it to enable this type of search using known technologies, publishing the full dataset on IPFS, and then building a frontend hosted on IPFS. If someone wanted a full search index, they could pin that folder to have it locally available. This is useful in cases where someone wants to host it to make it easily accessible.
We have some benchmarks that are great user experience, but for some others, it was more a proof of concept than a usable tool. For example, when we hosted it on one node, it was quite slow at times. With 3 nodes, the content was already faster to access: it took a few seconds to get to the first page, and then it would go on quickly. With 4 nodes, we needed a second to download the first page, and subsequent pages took about 250 milliseconds. Of course, for already searched keywords, the results appear faster, so you can see them as they are discovered. The more people use the index, the faster it becomes.
What downsides did this approach have?
Well, it’s a fully distributed search index in the sense that the index itself is shared and it’s a bit strange to even be possible and a bit strange that it actually works haha.
However, the search index is built centrally by one entity that says: this is the index, you should trust us. The same way as it is with ipfs-search.com. Suboptimal but this is the reality for now.
The other downside is updating the index – every month it will be full of new pages, hence the data you cached and shared with others will carry no value anymore. So that’s a bit problematic. But improvements are very feasible and possible.
Another one is the fact that we didn’t build a full-text search; on ipfs-search.com, you very often search for a topic rather than a title you already know. A full-text index would be more useful for end users.
If we imagine a fully distributed search engine, what would it look like in practice?
When you search a query, you have a need for certain parts of a large database. What happens now is that Elasticsearch, which is used server-side at ipfs-search.com, gets a set of results, and to compute that, it will need to use parts of its index. It will combine them and come up with 50 results that might be of interest to the user.
In the semantic web, where the idea that everything should be decentralised and discoverable is prevalent, the approach would be different. It would be to take the search index and cut it into a million pieces that the user can retrieve.
Imagine you view an image via ipfs-search.com. This means that the image will be in your cache for a while and then forgotten. But in case someone else asks for the same image earlier, you can offer it to them.
The same will happen with all tiny pieces of the index you downloaded, as long as they are cached, you can share them with other peers, and effectively host them.
In case ipfs-search.com ceases to exist, the index remains alive, without pinning it anywhere, and will still be available through peers that are using it. If enough people have its bits and pieces, with some luck we will still have a full index.
It’s worth mentioning that even if some pieces are missing, it means that they were of no interest to the user, no one was looking for them.
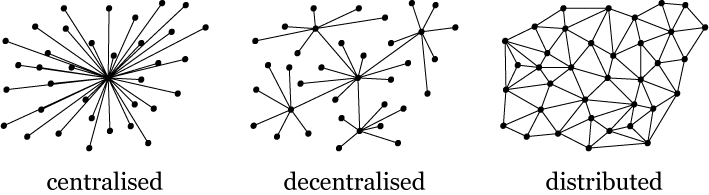 |
|---|
| CC BY-SA 3.0 http://creativecommons.org/licenses/by-sa/3.0/, via Wikimedia Commons |
It is also not a stretch to imagine that a user will trust and choose certain indexes. For example, a user decides to trust ipfs-search.com, and also, their university’s search engine, and wants to combine the information gathered by these indexes. It is possible to create a space, where people can search through entities they want to. If that’s possible, it’s also possible to have a distributively constructed search. And it is not only about trust because sometimes you want to look for something via a source you don’t trust so much.
When we did the experiment, we found it exceptional that we could have something working without a huge central database that provides search, that can be commoditised and done by people… Go back 15 years, and it would be a threat to some major industries.
So, there is hope?
There is hope. A lot of it. If people want their communities to find stuff, and they don’t want to contaminate other communities with it, then we can build a distributed search. There will be a lot of research on human behaviour to be done and experiments like “does it explode today or not?”.
But I think it’s feasible and the technologies we have today are a good start. It’s extremely promising. But also we need to be very realistic – this is not something that is going to replace the main search engine within five years or so, because there will be a lack of functionality. If there is full-on research into it, then yes, totally. But this is not what is happening right now.
Do you and your team have any plans regarding running an expanded version of the current experiment?
If possible, we should go towards larger data sets. We notice exponential growth in the search index, and we also noticed that the way how we now build the search index can’t keep up with the growing database, it gradually becomes slower. It was the first experiment and we know how to counter the issues. Great results for a proof of concept.
We’ll have to see what the performance impact is of running across nodes at some point and what the impact is for full-text search, but we are very much in the game.
Further reading/watching:
- https://github.com/redpencilio/ldes-publisher-service
- https://github.com/redpencilio/ldes-prefix-autocomplete
- https://github.com/redpencilio/fragmentation-producer-service
- Ted Talk with Pieter Colpaert
How to run the application at home:
Preparing your IPFS daemon
The ipfs daemon can be configured. The way the application is currently hosted, it expects Access-Control-Allow-Origin or be set to *. This means any website can request any resource over IPFS. This shouldn’t be able to cause any harm when on public IPFS.
Easy route
ipfs config "Access-Control-Allow-Origin" "[*]"
Complete route
All settings can be configured through
ipfs config edit
This guide assumes you have the IPFS companion up and running with your own gateway and that your gateway has the Access-Control-Allow-Origin set to ["*"] as in:
{
"API": { "Access-Control-Allow-Origin": ["*"] }
}
Opening up the frontend
We assume you’re running the IPFS companion which redirects calls to ipfs:// to your local daemon.
Visit the frontend at ipfs://ipfs/QmXiKm8Y37YyNWsX3bMNpMEHuoUCKWkWvPVUFGP2Ex9kq6
Entering strange information
The frontend allows you to browse different indexes. We’ve made the starting point of a full-text search index available at https://gateway.ipfs.io/ipfs/QmbJT8MRZnyv8gYQmcmUk8FYdgqJFwrn6634CCtxiPd3xr/1
under the ttl format.
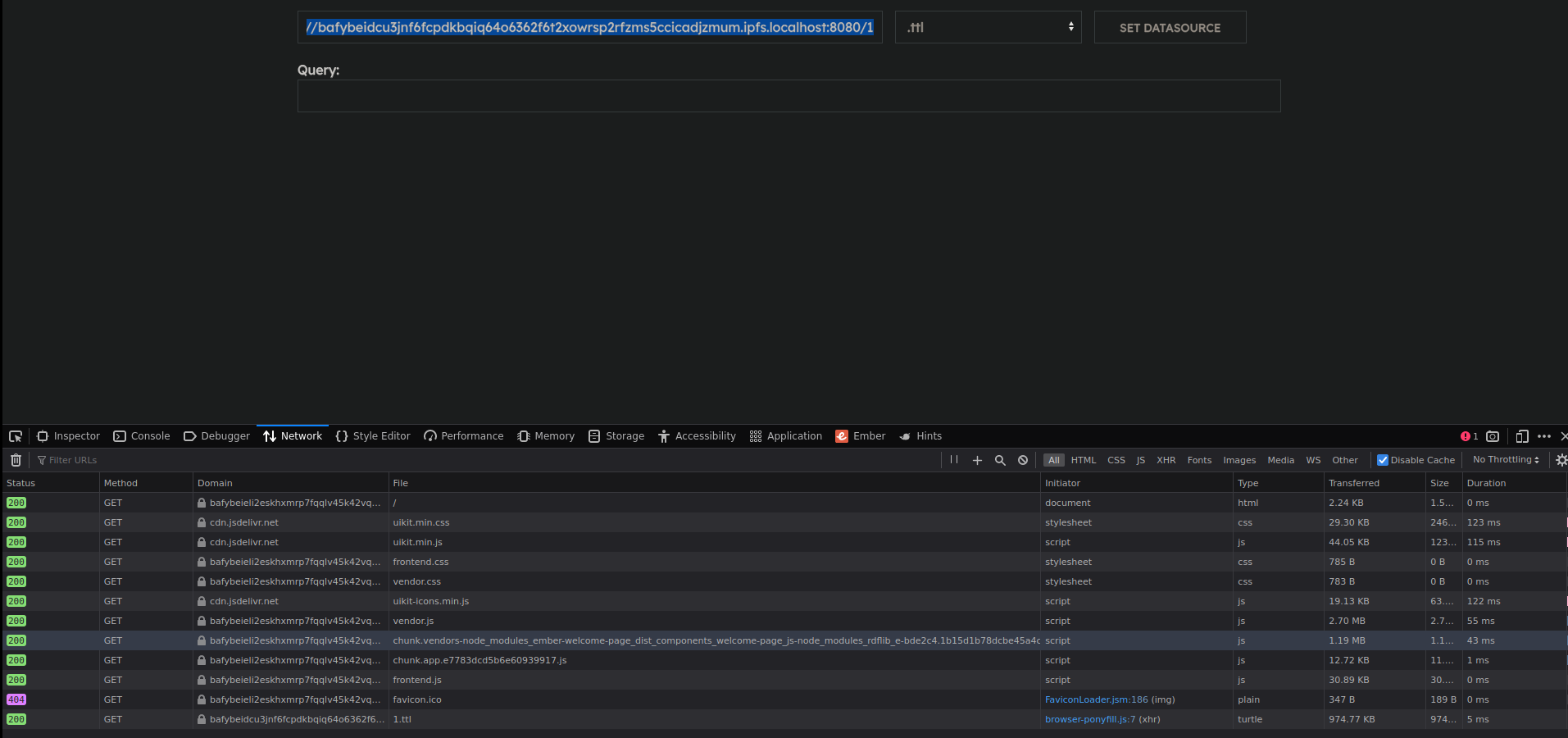
Enter the aforementioned URL in the first text input.
Pick .ttl as a format and click SET DATASOURCE.
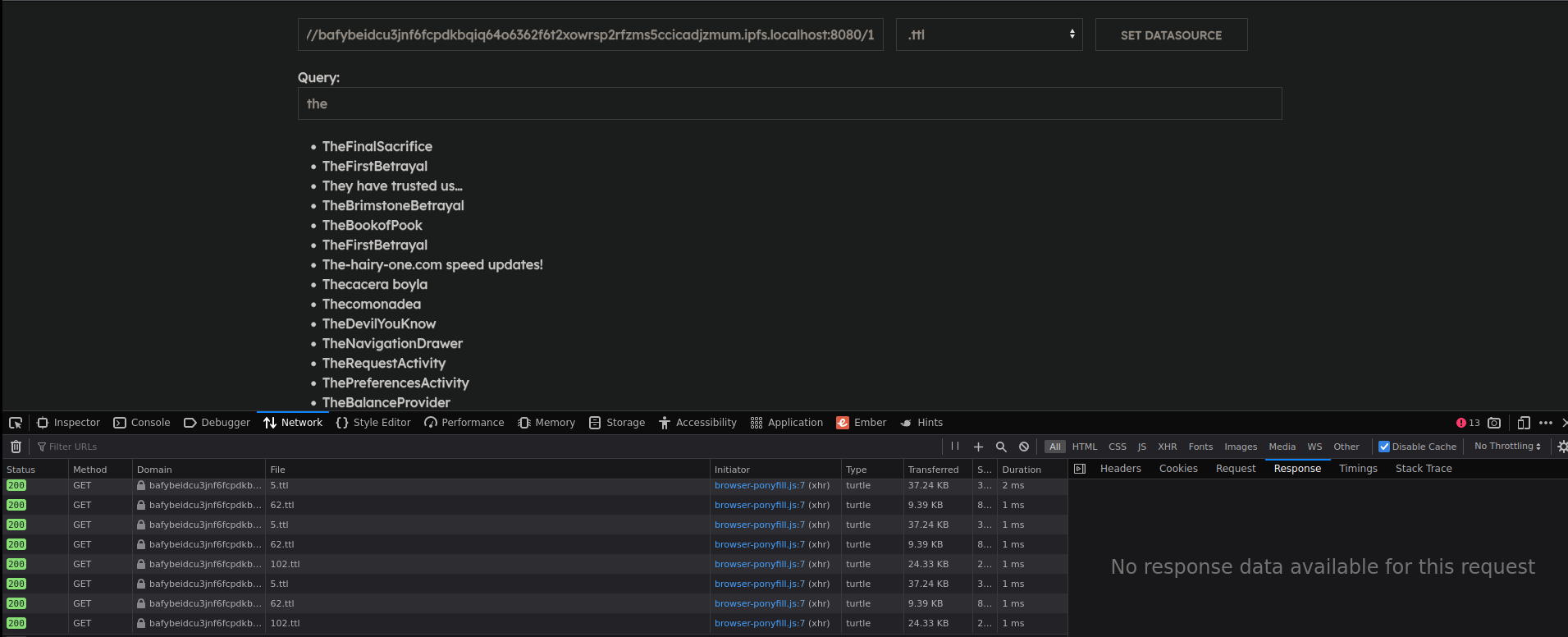
You can verify the first page was fetched by opening your network tab. Notice 1.ttl has been fetched.
Searching
You can now enter any search query. Results are fetched live using a prefix search index.
As you type results, the pages for each letter of the query are fetched. Sometimes the network doesn’t find its way and it takes a while to find the specific page.
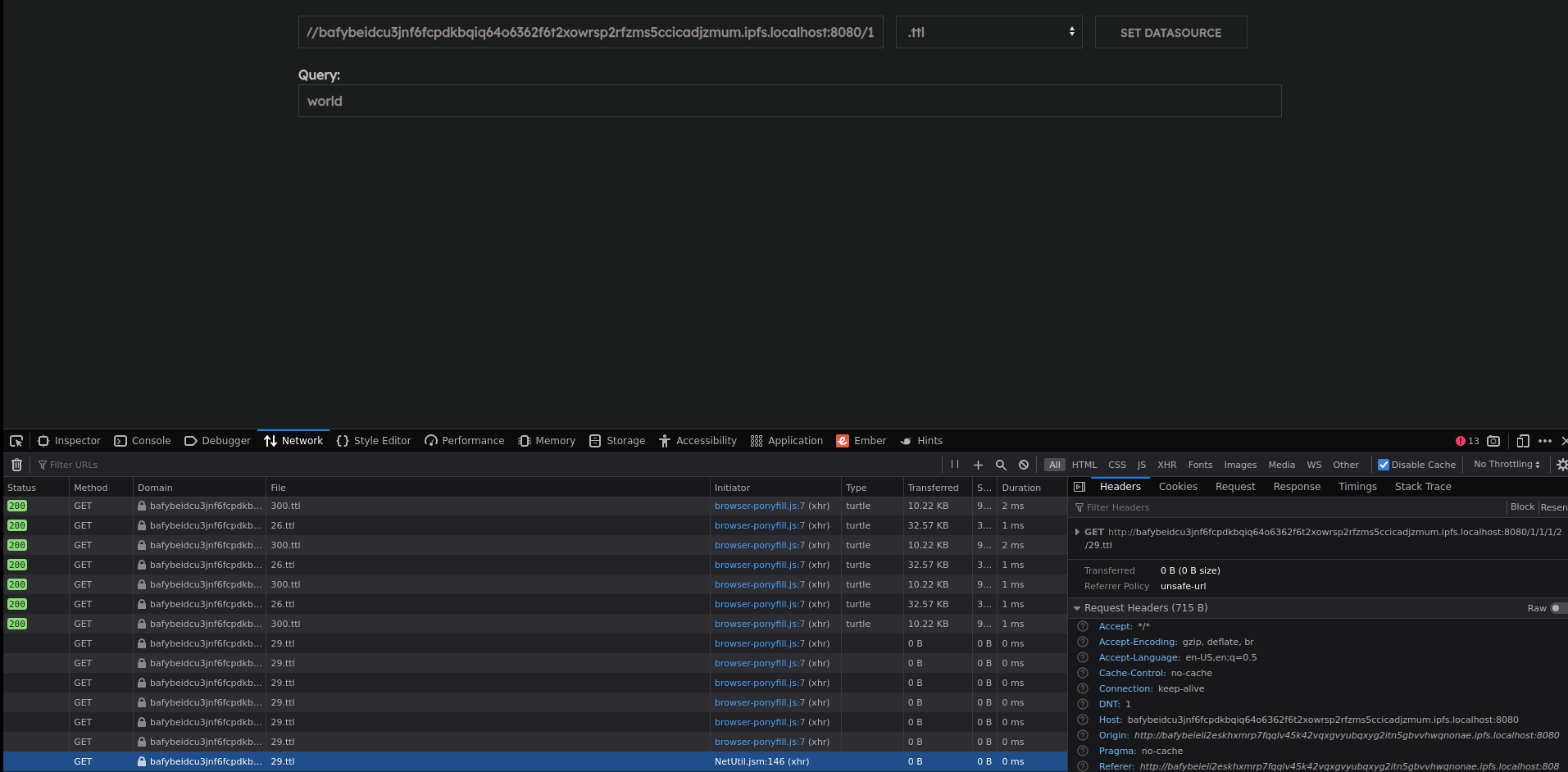
And sometimes it goes very fast: