Breaking the silent consent - closer to the free Internet, an interview with the founder of IPFS Search
Online privacy and security are too rarely questioned by ordinary users. Taking them for granted comes from the fact that most people believe they have control over the information they share. Most of us live in silent consent to something that, in a non-virtual society, we would never give permission for. Not everyone has the time to use alternative tools, search engines, browsers, plug-ins, and a range of security features. Learning new things takes time, and with that, as with everything else, the primacy of convenience wins out.

Still, there is a safer future for the Internet, and it’s us, users, who should fight to bring this future into today.
Our guest is Mathijs de Bruin, founder, and inventor of IPFS Search, a search engine indexing the open-source Interplanetary File System which describes itself as “a peer-to-peer hypermedia protocol designed to preserve and grow humanity’s knowledge by making the web upgradeable, resilient, and more open.”

ZM: Maybe before we really start this talk, tell us how this description of the project you contribute to, resonates with you?
MdB: I think what Juan Benet is striving for is something that we have been looking for in the hacker movement for a long time.
So, as hacker technologists, we are the people that maintain the Internet infrastructure. For most users, the Internet is something that is just “there.” Like a black box, you put a few cables together and the magic happens. But for us, it is different, we know what’s going on inside this box.
Let’s remember that initially the Internet was set up as a research protocol, among research institutions, mostly by the US government. It was created to be resilient against outsiders’ attacks, specifically nuclear attacks. But it wasn’t set up to be resilient to censorship or cyberattacks.
 |
|---|
| Internet backbone as of January 15, 2005. CC BY 2.5 |
The way I see it is that the only reason we have free internet right now is because a lot of people that are maintaining core infrastructure have very strong morals and principles. It is not accidental that the Internet used to be an open, free protocol. Now we have mobile providers who offer free Internet for Facebook, YouTube, and Spotify, but not in general. And at the same time, we see that Facebooks and YouTubes of this world are applying various kinds of censorship to a frightening degree. We are talking about free, democratic societies. It’s a complete erosion of civil liberties that… we didn’t really have until the advent of cyberspace, and now we are already looking to lose them. We’ve been worried about that in the hacker community for a long time.
 |
|---|
| CC BY-NC-SA 2.0 by Florian Hauschild |
In countries that are not pretending to be free, the Internet has been cut off or censored shamelessly. For example, Turkey blocked Turkish Wikipedia because of an article about state-sponsored terrorism. Spain has been blocking access to information about the referendum in Catalonia, at one point Russia blocked 25% of the Internet because people were saying things the government didn’t like on Telegram.
You should also know that most of the Internet is hosted on Amazon servers. This is another topic, people think that Amazon sells books and toilet brushes, but actually, they sell Internet infrastructure – that’s their core business. And Amazon is an example of a company that doesn’t care about this freedom I mentioned above, they just want to make money. They are not apologetic about it.
So we have been saying for a long time, that the moment you buy into Amazon, the moment you buy into Facebook where it is OK to censor people and trace and track everything, there is no turning back. Governments, companies, and other entities… once they gain such power, they will never give it up.
In opposition to that, people like Juan Benet and people from the hacker community were thinking: OK, so we have torrents, where when you download a file or a film, you also upload it, and there is no official uploader nor downloader and no one can go to a single party and force them to take this file offline… this idea was behind IPFS.
People started to realize: wait, so if we use the same principles we used for torrents, and we use them to make a new kind of Web then censorship will become impossible. And at the same time, you don’t need these big companies anymore.
Imagine that every time someone is viewing the Gangnam Style K-pop video on YouTube it gets downloaded from somewhere on their computer. It has 4,387,208,147 views. Sick amount of data for no reason, it’s the same content transferred again and again.

Let’s make some assumptions. The video clocks in at 117 Megabytes. That means (at most) 274,286,340,432 Megabytes, or 274.3 Petabytes of data for the video file alone have been sent since this was published. If we assume a total expense of 1 cent per gigabyte (this would include bandwidth and all of the server costs), $2,742,860 has been spent on distributing this one file so far.
Source: HTTP is obsolete. It’s time for the distributed, permanent web by kyledrake
And now we arrived at another advantage of IPFS: If I make a video whose content is not politically correct, for example, for my government and I want to share this with the world, there is no one who could possibly take this down. Also, I don’t need to keep it on my server in my house.
I think we’ve covered some important issues here, each of which would probably lead us to an endless and interesting discussion, but let’s focus on a few points: you started talking about how we are vulnerable online, susceptible to tracking. About censorship, privacy… What else happens when we surf the web?
What’s been happening since 9/11 in the USA and every country aligned with the USA is that certain entities within the governments started to think that it is completely alright to forfeit fundamental human rights in general in the face of adversity, particularly terrorism. Suddenly it was alright to lock up and torture people and consider absolutely everyone a suspect. In the wider spectrum, it means that if you watch something “bad” on the Internet, you are susceptible to blackmail.
 |
|---|
| MEP’s demonstrating support for Edward Snowden, who unveiled the government’s extensive and generally unconstitutional domestic spying programs. CC BY European Union |
All these companies, like Google, Amazon, Facebook, Apple, etc. are not only obligated to give to any government entity all the information they collected but also to keep their mouth shut about it. Literally, everything gets stored. The stuff you did in the past, what house you want to buy, what car you drive, when you have your period, your consumption patterns … and there is a general acceptance of that mainly because people read too little science fiction. Vinay Gupta, a great thinker in many fields, regarding where we are as a technical society, said that the problem is that intellectual leaders of this world, people who studied literature have completely overlooked science fiction.
These leaders, Gupta claims, don’t know how information is propagated on the Internet, they don’t know about some systemic behavior of large centralized systems that’s really very important. A government that spies and knows everything about its own citizens is a different kind of government… We live in a world where AI trained in a specific task has by far exceeded human capacity.
Knowing all that, what are the security goals of IPFS Search, and which have already been achieved?
I think one of the things we are trying to hack is not so much technological, which is also why I have been talking politics this whole interview. I think the goal is to do for search what Wikipedia has done for encyclopedias.
The idea would be to have content discovery outside the platform capitalism domain, which is “We are connecting everybody with everybody, you have to go through me, and every time you go through me, you are paying with your attention, which is the most valuable token.” We want to challenge this model and make the search engine very inexpensive first, by making sure that what we make is very close to what users need and want, and second, by making sure that there is not only one place where all these servers run. We fully expect that as the content we put into our database grows, the log on our database also increases exponentially.
 |
|---|
| By: opensource.com |
But also when people that are putting content online start providing some searches, it becomes a decentralized protocol like Bitcoin, for example. We want to set up an incentive system, possibly backed up by a blockchain, possibly backed by a funky thing called Zero-Knowledge proof, where you can actually make sure that a bunch of people can run a search engine, and they can do it in a way where even if it scales up, even if there are lots of people and some of them don’t play by the rules, you can still get reliable search results. This is our long-term vision.
So again, we have a lot of people involved in the process of development. IPFS Search is based on the idea of a community project.
Yes, we are an open-source project, our model is a bit like Wikipedia, but of course, we currently don’t have an index or a catalogue that people can edit just like that. We would like to have some users’ feedback in our actual search results, but there are some technical problems to solve first, so we prefer to focus on the search for now. As for a community contribution, if you want to change something in the user interface, you want to have a filter or suggest something, you can just propose it via our GitHub repository.
 |
|---|
| Giulia Forsythe, redrawn by Asiyeh Ghayour under CC0 1.0 |
{kind=link}
We really love it if you want to improve our documentation or contribute ideas, that’s super welcome. But at the same time, we know that at some point we might face various kinds of censorship. And this is why we publicly share the entire index of our search engine. No search engine has ever done that. So we are not open-source only because of our code, but also because of our index. Similar to OpenStreetMap, we have the same license for data. It means that if somebody wants to take us down or censor us, there is nothing in the way of other people to fork us, copy and paste our entire search engine. If they take it and make a better search engine based on ours, the only thing they need to do is to share their improvements and data set. It’s a double-decentralized principle.
📢 Let’s summarize what we have said until now: We are focusing on having a working search engine that other people can copy and paste, and later together with other people we want to make it properly decentralized.
Do you have any particular cooperation on the horizon right now?
Certain niche search engines that target a user who has a bit more knowledge about privacy or is into decentralized Web, such as Brave or DuckDuckGo, are interested in having indexing of decentralized Web.
So, we want to see if we can handle web-scale traffic in order to start such cooperation.
If you were to look back, what happened in the project that is worth mentioning?
Interesting question, if I look back, indeed a lot of things have happened. In the team, our social structures, how we are working together, etc. But what’s visible is the new front-end we launched and a new, better structure, beyond basic usability, that allows us to receive contributions but also work faster, make improvements, be more agile, and closer to users.
 |
|---|
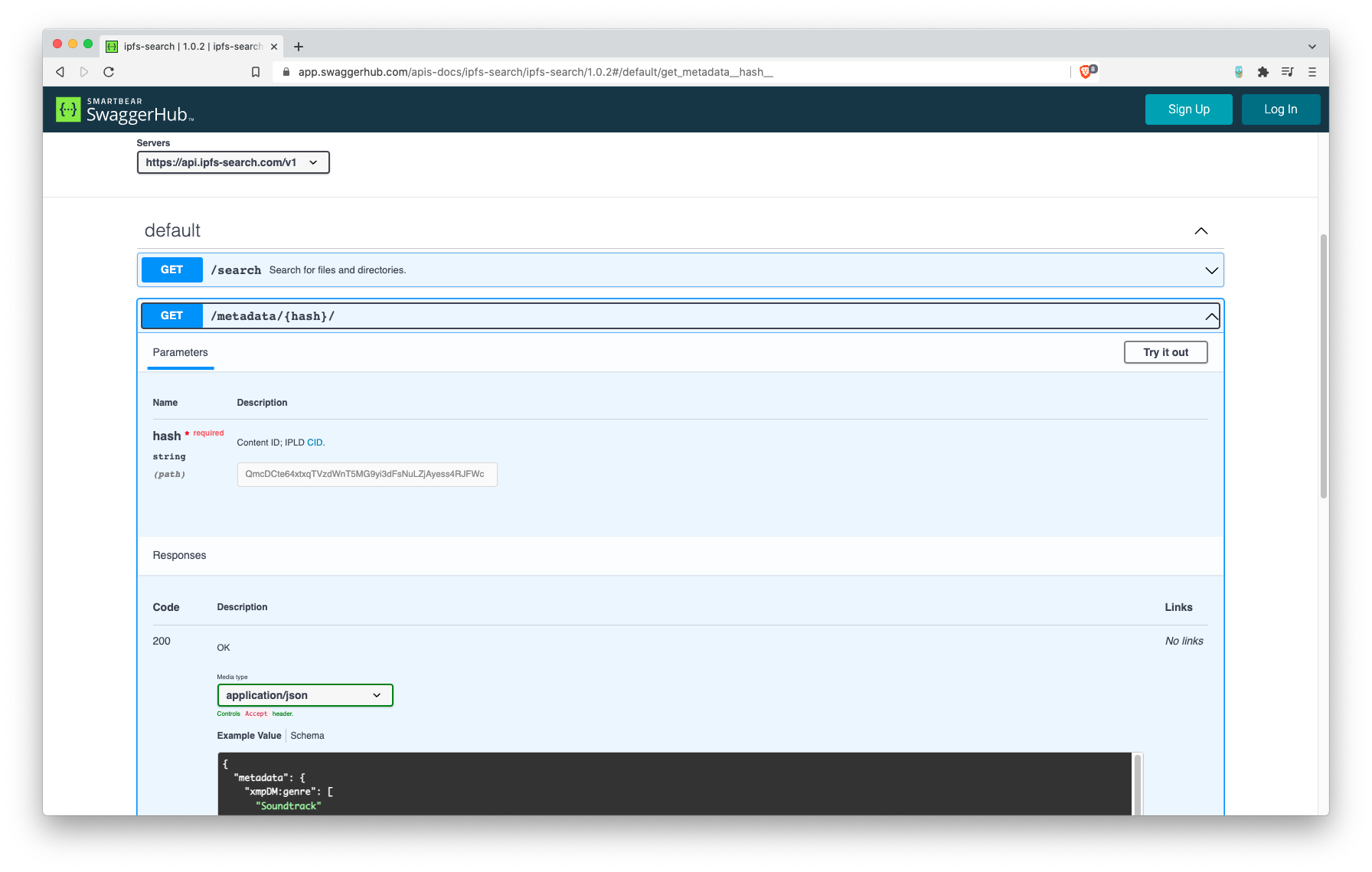
| On https://api.ipfs-search.com you can play freely with our API. |
One of our goals also, instead of having a normal front end, is to offer our services to the world, so people can integrate our search engine into their own websites. We already have an API, so developers can play with our files, directories, and all data and metadata.
What else has happened is porn. What we noticed quite quickly is that some really weird, but not illegal or frightening, stuff got published on our search engine. That’s become a bit of a problem, because we don’t primarily want to be a porn search engine, haha.
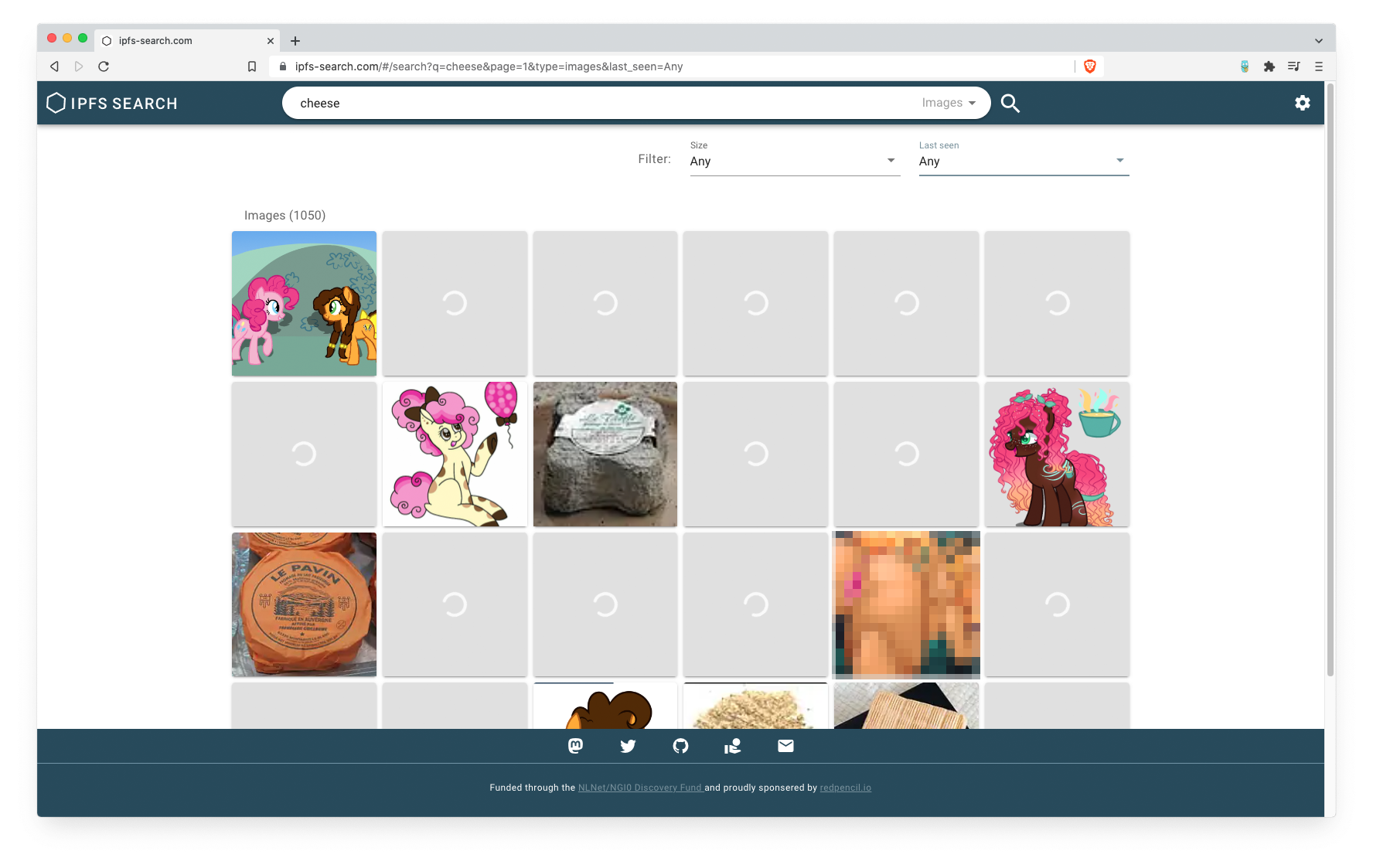
To solve it, we implemented a filter, that you can technically also run in a browser, that is using AI to analyze pictures whether it is porn or not. It doesn’t work perfectly, but we might also get to the point where we improve the model ourselves. But what also came with that is using AI to classify our content, and this means we can use it also to do similar stuff with music, to know the genre and group music together, to navigate between text files, we have. It’s very interesting because AI is coming from a point where it was something abstract, that only Google had the power to use, to publicly available models that you can implement. It all leads us to the internal discussion about applying censorship and becoming evil, but we have found a way: we are only blurring the pictures and giving the users choice to switch the filter off.
What are your and your team’s plans for the future? What do you want to achieve within the next 6 months?
We want to go to The Moon and back, haha.
I think in the next year, because of the way IPFS is increasing its popularity, we are going to start growing exponentially. Or IPFS will fail. This means that someone will do the same thing better, and we will move to theirs, our infrastructure is ready for that.
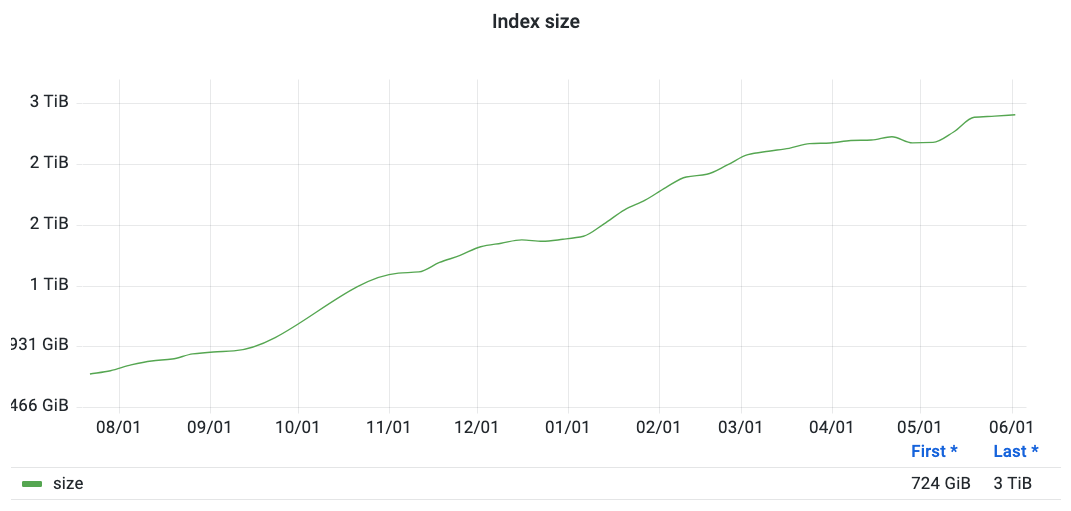 |
|---|
| Over the past year, we’ve more than tripled our index as we’re scaling up to a 50-node cluster. |
I don’t think that will happen, though, because there are large groups that have been actively supporting IPFS. Also, the NFT ecosystem is running on IPFS, there is a lot going on for them. So, if the amount of available content grows exponentially, it means that we have to grow our infrastructure exponentially. We need to be able to expand and have proper frontend and backend teams to also address more features and check what our users need, and try some solutions.
So far we have been three friends working together, like a hobby that grew out of hand, but now we are looking into starting a company or a foundation. Actually, what we would like to be is something that so far doesn’t exist legally, a social enterprise – an organization that at the same time tries to make money while also guaranteeing certain non-monetary, societal goals. So it will be a personal challenge and also a challenge for us as a team.
It will be a very interesting and tricky year for us.